
Dark data isn’t created because storage is expensive or platforms can’t handle volume. It’s created because organizations are forced to decide too early what data means and how it will be used. When there is no immediate answer, the data doesn’t get modeled, doesn’t get integrated, and eventually doesn’t get trusted, so it stays in the shadows.
Dark data is usually treated like a technical nuisance:
unused tables
forgotten files
logs nobody queries
event payloads that never make it into a dashboard
The conversation quickly turns into tooling, cheap object storage, archiving policies, retention schedules, and lifecycle rules but that framing misses the point.
In other words, dark data is not a storage problem. It is a strategy problem.
What Dark Data Really Is
Dark data is often misunderstood as low-quality or irrelevant data. It is neither. Dark data is data whose business meaning is not yet agreed upon or not yet known. It exists because systems generate more data than organizations can immediately interpret. Operational signals include:
operational events
logs
historical snapshots
semi-structured payloads
behavioral traces
These are not failures of data engineering. They are natural byproducts of modern, complex systems.
Dark data grows because the future is unpredictable. New questions emerge, regulations change, business models evolve, and analytical needs shift. Any architecture that assumes stable questions at ingestion time will inevitably leave data behind.
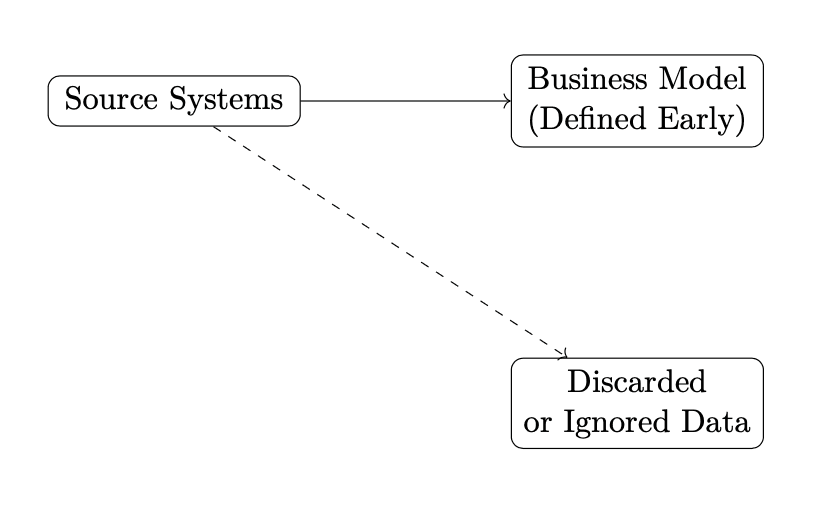
The Root Cause: Early Semantic Commitment
Most data platforms are built around a single assumption: data must be understood before it is stored. Dimensional models, tightly defined schemas, and downstream-focused pipelines all require early agreement on business definitions. This works when requirements are stable. It fails when they are not.
When meaning must be decided upfront, organizations face a trade-off:
delay ingestion until consensus is reached
discard anything that does not fit today’s model
Both choices destroy optionality. This is where dark data is born. Not from neglect, but from architectural rigidity.
Capture First, Interpret Later
A different strategy starts with a simple principle: capturing data and interpreting data are not the same activity. Capturing data means preserving facts as they occurred:
identifiers
relationships
attributes
timestamps
provenance
Interpretation is a downstream concern that can change over time. Separating these concerns allows organizations to ingest data without committing to a single future. Meaning can evolve without rewriting history.
This is not about modeling everything upfront. It is about modeling just enough structure to keep data intelligible later.
Why Data Vault Changes the Equation
Data Vault was designed around a simple but powerful separation: capturing data and interpreting data are not the same activity, and they should not be coupled.
Instead of forcing business meaning at ingestion time, Data Vault focuses first on preserving what can be known with certainty. It captures stable identifiers independently from descriptive attributes, models relationships explicitly rather than implicitly, and treats context as time-variant rather than overwriteable. In doing so, it avoids embedding assumptions that may only be valid for a short period of time. This separation has important consequences.
By anchoring data around stable identifiers — what Data Vault calls hubs — the platform establishes durable reference points that survive business change. Names change. Classifications evolve. Definitions shift. But the underlying entities remain, and their identities do not need to be redefined each time the organization reorganizes or reinterprets its data.
Relationships are elevated to first-class concepts through links. Rather than being hidden inside transformations or downstream logic, relationships are captured explicitly and allowed to change over time. This makes evolution visible instead of destructive. When relationships shift, the platform records the change rather than silently rewriting history.
Context is handled through satellites that are explicitly time-variant. Descriptive attributes are not treated as static truth, but as information that reflects what was known at a particular point in time. Corrections, late-arriving data, and evolving rules are expected, not treated as exceptions. History is preserved rather than flattened.
The result is a structure where lineage and time are inherent properties of the data, not reconstructed after the fact.
When new questions arise, as they inevitably do, existing data does not need to be reloaded or reinterpreted retroactively. The past remains intact, and new meaning can be layered on top without invalidating what came before.
Capture remains stable. Interpretation evolves.

In this model, uncertainty is no longer a reason to delay ingestion. Data can be captured even when its future value is unclear, because the architecture is designed to accommodate evolving understanding. Dark data is no longer excluded by design; it is absorbed and preserved until its meaning becomes clear.
Metadata Turns Dark Data into an Asset
Storing data alone does not eliminate darkness. Without context, even well-structured data remains opaque. Metadata is what turns captured data into something that can be revisited, trusted, and reused. Metadata records:
where data came from
when it arrived
how it relates to other entities
how its interpretation has evolved over time
Without this information, historical data quickly loses its usefulness, even if it was preserved.
When metadata is treated as documentation, it provides limited value. When metadata drives automation, it becomes transformative. In a metadata-driven environment, rules, validations, and transformations are defined once and applied consistently. New interpretations can be introduced without touching historical data. Quality checks can evolve without rewriting pipelines. Lineage does not need to be inferred; it is already there.
This is especially important for dark data. Data whose value is not immediately obvious often lacks ownership, validation, and clear semantics. Metadata allows that uncertainty to be made explicit rather than ignored. The data can be captured, classified, and governed incrementally as understanding grows.
Over time, what was once dark data becomes contextualized data — not because it was reloaded or reprocessed, but because meaning was added deliberately and transparently.
In this sense, metadata turns dark data from a liability into a deferred asset. The decision is not whether the data is useful today, but whether it is preserved well enough to be useful tomorrow.
Why This Matters
Dark data used to be an analytics inconvenience. Today, it is an AI liability. Machine learning systems depend on historical depth, contextual richness, and reproducibility. If data was discarded or flattened because it lacked immediate value, the consequences are permanent:
training sets cannot be reconstructed
drift cannot be explained
models cannot be audited
Dark data is not just future reporting value. It is future intelligence capacity. Storage costs are negligible. Re-ingesting history is expensive or impossible. Reconstructing lost context rarely succeeds.
The true cost of dark data is paid later: missed insights, repeated re-platforming, brittle pipelines, and decisions made without evidence that once existed. Architectures that force early interpretation optimize for today at the expense of tomorrow.
Conclusion
Dark data will never disappear. The world produces more signals than can be immediately explained. The strategic question is not how to store less data, but how to design systems that can hold uncertainty safely.
When …
data can be captured without commitment
meaning can evolve without rewriting history
metadata makes change cheap
… dark data stops being a liability and becomes a strategic reserve.
