
AI trained on non-integrated data will produce enterprise-inconsistent and potentially wrong outcomes. This is not a limitation of AI models themselves. It is a consequence of fragmented enterprise data foundations.
In the previous article (Lakehouse vs Data Warehouse: One Platform, Different Workloads) , we explained why modern lakehouse architectures support multiple workload types and why the governed workload remains essential for enterprise analytics.
This article builds on that foundation by examining why enterprise AI can only be trusted when it is grounded in that same governed, integrated data.
What Does a Reliable Data Foundation for Enterprise AI Require?
A reliable data foundation for enterprise AI is built on four interdependent components. Each is necessary. None is sufficient on its own.
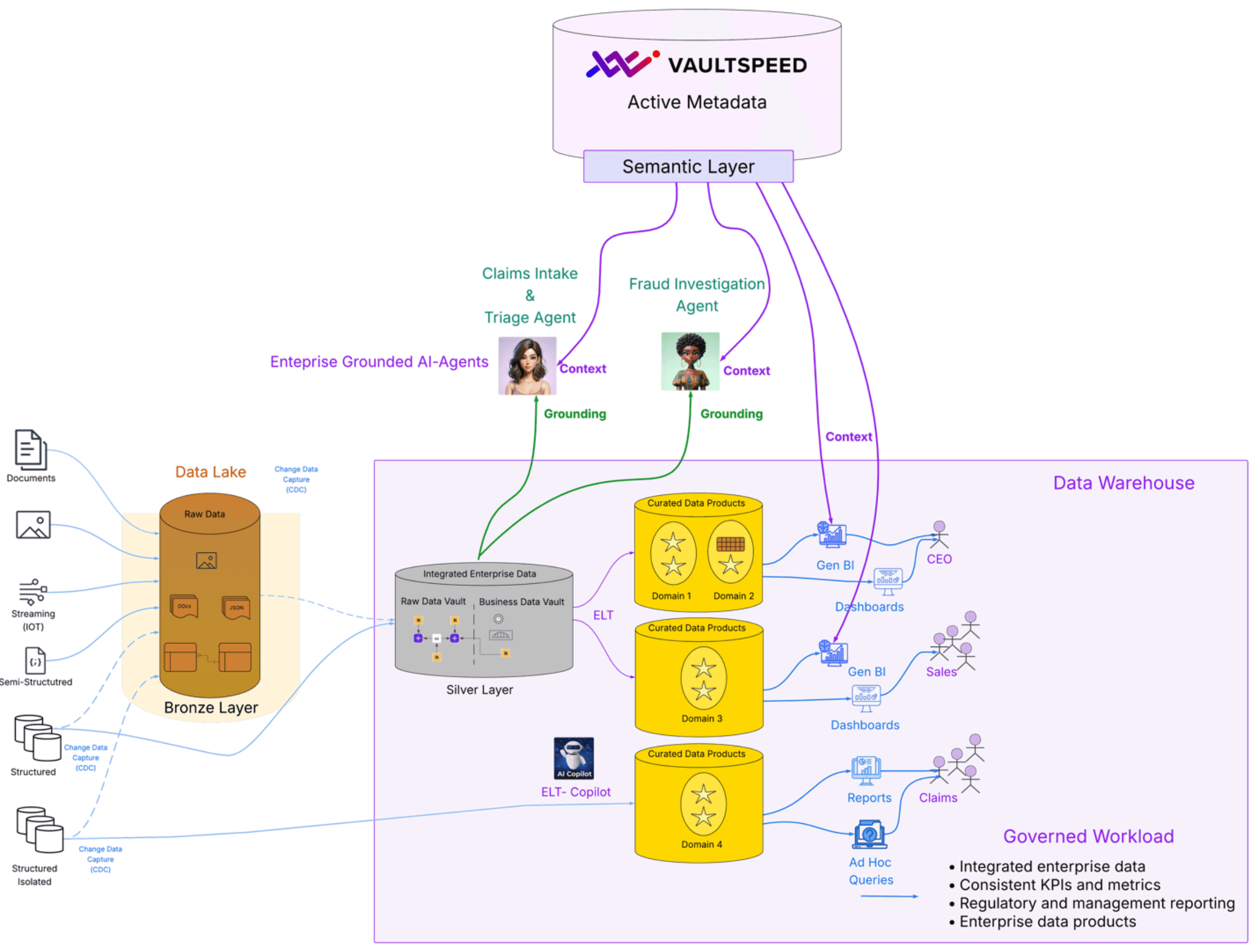
Integrated data: a governed workload that unifies data across source systems, aligned on business keys and historized correctly over time.
Active metadata: explicit transformation intent, lineage, and change history that keeps context synchronized with the data itself.
Explicit semantics: formal definitions of entities, metrics, and relationships so AI knows not just what the data is, but how it should be interpreted.
A semantic layer: a stable contract between governed data and consumption, ensuring BI tools, Gen BI, and AI agents all operate from the same enterprise-approved definitions.
The sections below explain why each component matters and why none can be replaced by prompting, inference, or agent frameworks alone.
Grounding AI in Enterprise Facts
Artificial intelligence has become remarkably good at generating answers, explanations, and recommendations. Yet in many enterprises, AI initiatives struggle to move beyond impressive demonstrations into trusted, operational use.
The reason is rarely the AI model itself.
The real problem is that AI is often asked to operate without a stable foundation of enterprise truth. When that happens, AI does exactly what it is designed to do: it fills gaps with assumptions. The result may sound convincing, but from an enterprise perspective it is often inconsistent, contradictory, or simply wrong.
This is where the concept of grounding becomes critical.
Grounding means forcing AI to base its reasoning on trusted enterprise facts rather than on fragmented data, generic knowledge, or what merely sounds right. In an enterprise context, this is non-negotiable. Decisions, compliance, reporting, and automation all depend on data that is consistent, auditable, and aligned across the organization.
That level of trust can only come from integrated data.
Enterprises generate data across many systems, each with their own structures, keys, and interpretations. Without integration, AI has no way of knowing which version of a customer, transaction, or metric is authoritative. It will combine incompatible signals and still produce a fluent response. This leads to a simple but unavoidable conclusion:
AI trained on non-integrated data will produce enterprise-inconsistent and potentially wrong outcomes.
Why the Governed Workload Exists
This is exactly why the governed workload exists. The governed workload is where data is integrated across sources, aligned to enterprise business keys, historized correctly over time, and validated for quality. It is the foundation that powers regulatory reporting, management reporting, operational analytics, and enterprise KPIs.
In other words, it represents the enterprise’s shared understanding of reality — the only version of the truth that AI can safely rely on. But integration alone is still not enough for AI.
From Integrated Data to Meaning
Even perfectly integrated data does not explain what it means. Tables and columns cannot tell AI why a metric is calculated in a particular way, how entities relate across domains, or which rules matter in which context. Without that meaning, AI may use correct numbers but interpret them incorrectly.
That meaning lives in metadata.
When the governed workload is automated from a formal model, metadata becomes more than documentation. It becomes active context: semantic definitions, relationships, transformation intent, historization logic, and lineage — all kept in sync with the data itself.
For AI, this metadata is essential. It explains not only what the data is, but how it should be interpreted and used.
Why Active Metadata Only Exists in Automation Platforms
Metadata is often treated as something passive: descriptions, tags, lineage diagrams, or glossary entries created after the fact. While useful for humans, this form of metadata is not designed to drive systems. Automation platforms require something fundamentally different.
To automatically generate integration logic, transformations, and data products, metadata must be complete, precise, and executable. It must capture not only what the data looks like today, but why it looks that way, how it was derived, and how it has evolved.
This defines an active metadata store. An active metadata store contains:
Formal definitions of entities, attributes, and relationships
Explicit transformation intent, not just resulting SQL
Historization rules and temporal behavior
Dependency structures across layers
Ownership of logic by model rather than by code
Most importantly, it contains the full history of change. Automation platforms must know:
When a source attribute was added, removed, or modified
Which generated objects depend on it
Which logic must be regenerated
Which logic must remain untouched
Without this change history, safe regeneration is impossible. Passive catalogs observe change after it happens. Active metadata drives change as it happens.
Grounding and Context Must Work Together
This is where grounding and context come together.
Grounding ensures AI uses the right facts.
Context ensures AI understands what those facts represent.
One without the other is insufficient.
Grounding without context leads to correct numbers with wrong interpretations. Context without grounding leads to eloquent explanations of incorrect facts. Only when both are present can AI reason consistently, explain its outcomes, and be trusted at enterprise scale.
The Role of a Semantic Layer
With integrated data and explicit semantics in place, a semantic layer can be generated on top of the governed workload. This layer exposes business entities and metrics consistently and acts as a stable contract between data and consumption.
BI tools, Gen BI, and AI agents can all rely on the same definitions, ensuring that insights and decisions remain aligned across the enterprise. For AI, this semantic layer is critical. It constrains reasoning, prevents metric drift, and ensures that answers always map back to enterprise-approved meaning.
Is a Semantic Layer Really Required for AI?
A natural question is whether a semantic layer is truly required for AI, or whether AI can derive enough context on its own. Technically, AI can operate without a semantic layer. By analyzing documents, naming conventions, examples, and prompts, AI can infer meaning and produce seemingly useful results. This often works well for experimentation, exploration, and explanatory use cases.
However, inference is not the same as understanding. When meaning is inferred:
Definitions become implicit and unstable
Metrics drift silently
Results depend on prompts rather than enterprise rules
This may be acceptable for experimentation. It is not acceptable for enterprise use. If AI only explains, you may survive without a semantic layer. If AI decides or acts, a semantic layer is mandatory.
Why Semantic Standards Matter
As enterprises increasingly operate across multiple platforms, tools, and clouds, semantics can no longer be locked into a single vendor or technology. This is where semantic standards become important.
Initiatives such as Snowflake’s Open Semantic Interface (OSI) standardize how semantics are exposed and consumed by BI tools, Gen BI, and AI agents. This matters for a practical reason: portability.
Enterprises should be able to:
Change BI tools without redefining metrics
Evolve platforms without losing semantic consistency
Introduce AI agents without rewriting business logic
Standards do not create correctness. They preserve it. If the underlying data is not integrated and semantics are not explicit, standardization simply accelerates inconsistency.
Enabling Enterprise-Grounded AI Agents
This foundation of governed, integrated data enriched with explicit semantics and active metadata is what enables enterprise-grounded AI agents. These agents are not chatbots. They analyze situations, evaluate options, and support or trigger decisions. To do this safely, they must reason over:
Integrated structured data for grounding
Unstructured data for contextual enrichment
Semantic metadata for meaning and interpretation
Without this foundation, AI agents may be fast, but they will never be trustworthy.
Why Automation Changes the Equation
Historically, the governed workload arrived too late to support AI effectively. Integration took months, and by the time trusted data was available, experimentation had already moved on.
Automation fundamentally changes this dynamic.
Integration is delivered faster.
Semantics are enforced by design.
Metadata stays synchronized.
Change is handled predictably.
As a result, AI can benefit almost immediately from a trusted enterprise data foundation, without sacrificing governance or quality.
The Conclusion Enterprises Can No Longer Ignore
Enterprise AI fails because enterprises try to scale AI on top of non-integrated data and implicit semantics, not because of immature models. No amount of prompting, copilots, or agent frameworks can compensate for the absence of a governed data foundation.
Without integrated data, AI has no stable truth to anchor on. Without explicit semantics, it has no way to interpret that truth consistently. Without active metadata, it has no context to reason safely or adapt to change.
Standards like OSI are an important step forward, but they only amplify what already exists — they do not correct it. This reality is unavoidable:
AI will only ever be as reliable as the governed data foundation beneath it.
Enterprises that want AI to move beyond experimentation must make integration, semantics, and active metadata first-class, automated, and continuously maintained capabilities.
Only then does AI stop being impressive, and start being trustworthy.
