
AI trained on non-integrated data will produce enterprise-inconsistent and potentially incorrect outcomes. This is not a limitation of AI models themselves. It is a consequence of fragmented enterprise data foundations.
This article clarifies the architectural roles of the lakehouse and the data warehouse, and why both remain necessary in enterprise analytics and AI.
Architecture: One Platform, One Data Foundation
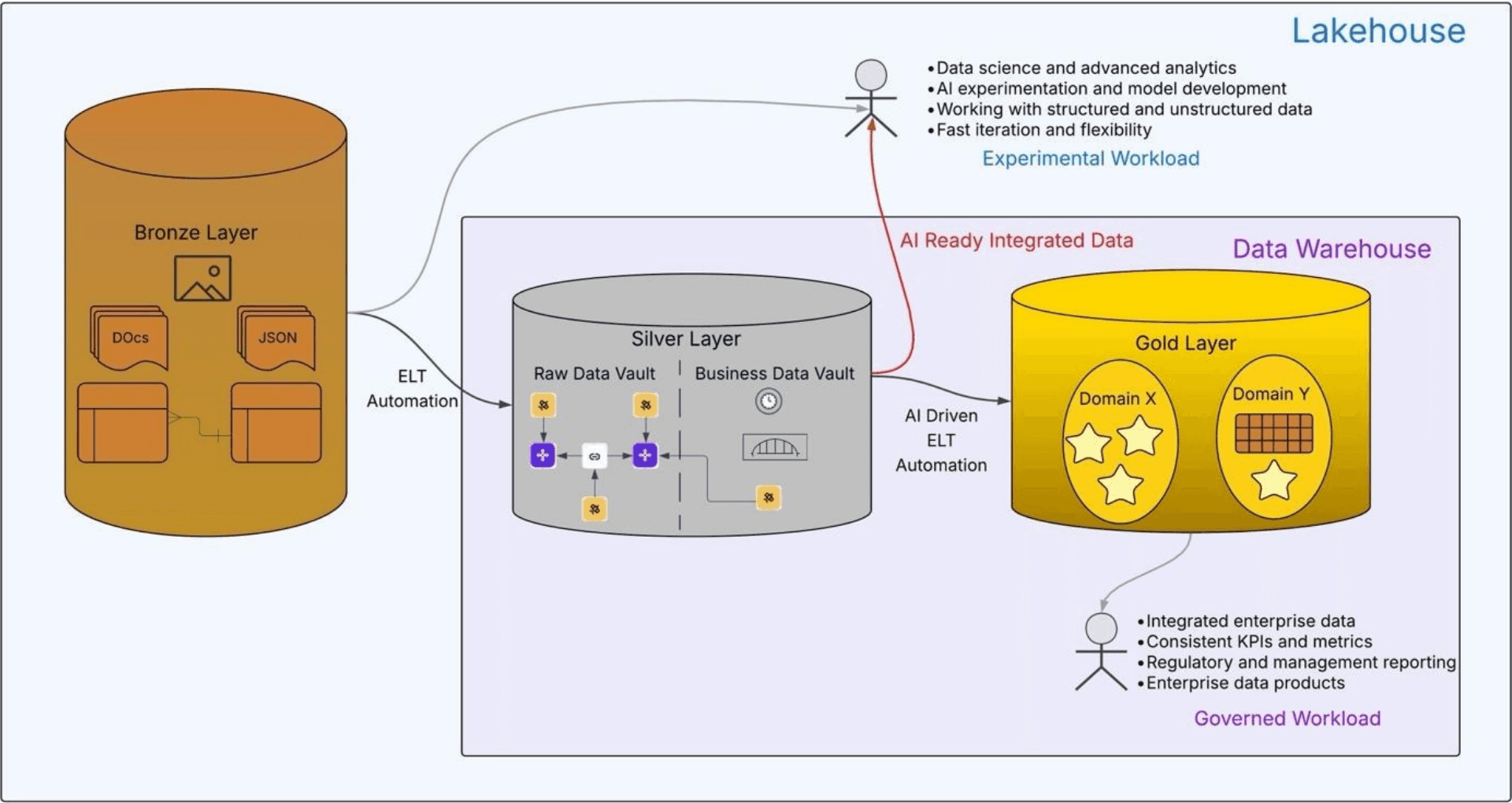
The term lakehouse originates from the idea of combining a data lake and a data warehouse on a single platform. Despite this, the industry still tends to compare lakehouse and data warehouse as if they were architectural alternatives. This comparison is a misconception.
A lakehouse is not an alternative to a data warehouse. A lakehouse is the platform that supports both data lake and data warehouse capabilities on the same storage and compute foundation.
From an architectural point of view, a lakehouse provides:
Data lake capabilities: open formats and support for structured, semi-structured, and unstructured data
Data warehouse capabilities: governed, integrated, trusted analytics
Within this architecture, the data warehouse remains a critical governed layer inside the lakehouse, built on the same platform services.
Once this distinction is understood, the “lakehouse vs data warehouse” debate naturally disappears. They are complementary components of a single architecture.
Why Different Workload Types Exist
The reason a lakehouse architecture is layered is not a matter of technology preference. It is driven by workload diversity.
In large enterprises, this pattern appears consistently: fundamentally different workload types coexist on the same data foundation, even when a single platform is used.
Large organizations typically operate multiple categories of workloads, each with distinct expectations, constraints, and users. This diversity explains why both data lake–oriented and data warehouse–oriented workloads continue to exist within the same architecture.
Experimental Workloads (Data Lake–Oriented)
Experimental workloads focus on discovery, exploration, and innovation. Their defining characteristics are flexibility and speed rather than strict governance.
Typical use cases include:
Data science and advanced analytics
AI experimentation and model development
Feature extraction from structured and unstructured data
Rapid iteration and hypothesis testing
The primary users of these workloads are data scientists, advanced analysts, and AI engineers.
These workloads primarily consume data from the Bronze layer, where raw structured and unstructured data is readily available. In some cases, they also consume integrated data when it is available and useful. The priority is freedom of exploration rather than deterministic behavior.
This does not mean experimental workloads should be governed in the same way as production analytics. Flexibility and freedom to explore remain essential.
Governed Workloads (Data Warehouse–Oriented)
Governed workloads focus on trust, consistency, and enterprise alignment. They represent the production side of data usage.
Typical use cases include:
Integrated enterprise reporting
Consistent KPIs and metrics
Regulatory and management reporting
Enterprise data products
The primary users include business users, management, regulators, and operational analytics consumers.
These workloads require deterministic processing, auditability, lineage, and a consistent enterprise view across domains and source systems. This is the role fulfilled by the data warehouse layer within the lakehouse architecture.
Integration as the Foundation for Trust and AI
Without integration, there is no single enterprise view of data.
Data remains fragmented across source systems and domains, leading to inconsistent metrics, conflicting insights, and unreliable analytical outcomes. This challenge becomes even more critical in the context of AI.
While unstructured data such as documents or images is often easier for AI models to consume, structured enterprise data without integration and context is extremely difficult for AI to interpret correctly. This is because entity meaning, relationships, and historical continuity are not explicit in raw or siloed enterprise data.
Integration provides:
Consistent business entities (such as customer, product, and contract)
Relationships across domains
Historical context
A shared enterprise meaning
Without this foundation, AI models inevitably learn inconsistent and sometimes contradictory representations of the enterprise.
In practice, organizations see this when AI models trained on fragmented enterprise data produce conflicting or non-reconcilable results across domains.
Automation as the Bridge Between Governed and Experimental Workloads
Automation fundamentally changes the relationship between governed and experimental workloads.
An automation capability applied to governed workloads does more than accelerate delivery. By industrializing integration, it produces explicit metadata that captures:
Structure and relationships
Business semantics
Historical behavior
Transformation logic
This metadata is not a by-product. It becomes context.
Because integration and transformation are automated, governed data becomes available much earlier and much more consistently than with manual approaches. As a result, experimental workloads no longer need to wait for long delivery cycles to benefit from integrated enterprise data.
Teams typically encounter this most clearly when experimental workloads begin to reuse governed data and discover inconsistencies that were previously hidden.
Data scientists and AI engineers can consume AI-ready integrated data enriched with enterprise context, while still retaining access to raw and unstructured data from the Bronze layer.
Speed, Context, and AI-Ready Data
Automation collapses the traditional gap between experimentation and production:
Governed data is delivered faster
Integration logic is consistent by design
Context is embedded through metadata
This allows AI to benefit almost immediately from the governed data foundation, rather than being limited to siloed or raw data sources.
In this model, governed and experimental workloads are not competing worlds. They reinforce each other:
Governed workloads provide consistency and trust
Experimental workloads drive innovation on the same integrated foundation
Bringing It Together
A lakehouse provides the platform whereas a data warehouse provides the governed integration layer. Automation connects them by delivering speed, consistency, and context—enabling analytics and AI to operate on a shared, enterprise-grade data foundation.
